
Understanding Send and Receive Buffers in Backend Development
In the realm of backend development, the efficiency and reliability of data transmission between clients and servers are paramount. A fundamental aspect of this data exchange involves understanding how send and receive buffers operate within the network stack. This article aims to demystify these concepts, explore common problems, and discuss various operational modes to optimize data handling.
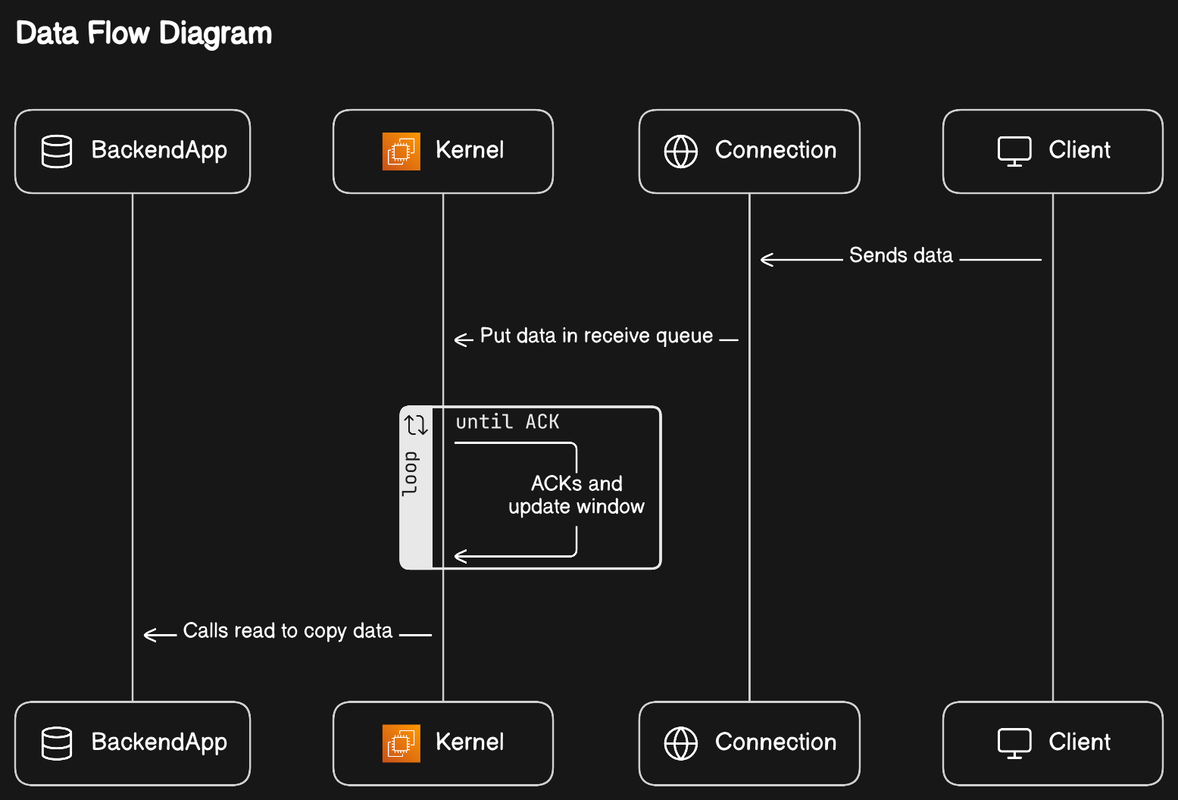
Send and Receive Buffers Explained
When a client sends data over a network connection, the data doesn't directly arrive at the application layer of the receiving server. Instead, it is temporarily stored in a receive buffer, a designated memory area managed by the kernel. This buffer acts as a waiting room, ensuring that data doesn't get lost if the receiving application isn't ready to process it immediately.Simultaneously, the kernel acknowledges the receipt of the data (often with a delay to optimize network traffic) and updates the window size in the TCP header to inform the sender about how much more data can be sent before requiring an acknowledgment. This mechanism is crucial for flow control and preventing buffer overflow.On the server side, an application must explicitly call a read operation to copy data from the receive buffer into its own memory space for processing. This step is where developers have direct control over how data is handled once it arrives at the server.
Common Problems in Data Reading and Sending
Backend Can't Keep Up
One of the most common issues in data transmission is when the backend application cannot read data from the receive buffer quickly enough. This lag can lead to the buffer filling up, which, in turn, forces the client to slow down its data transmission rate. This situation is undesirable as it can significantly degrade the performance of network applications, especially those requiring real-time data processing.
Full Receive Queue
A full receive queue occurs when the application does not empty the receive buffer fast enough, causing incoming data packets to be dropped. This scenario can lead to data loss or require the client to retransmit data, further complicating the flow control mechanism and reducing overall throughput.
Operational Modes for Optimizing Data Handling
To address these challenges, developers can employ various operational modes depending on their application's architecture and requirements:
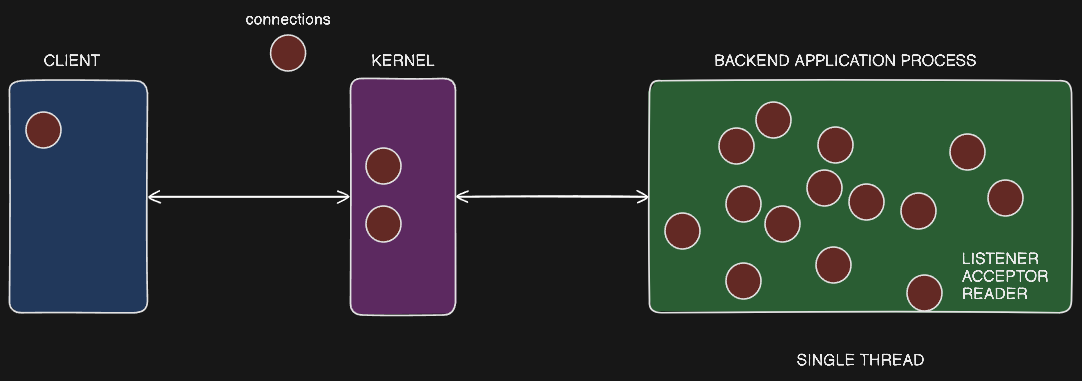
Single Listener/Single Worker Thread
Single Listener, Single Worker Thread in Node.js
- Node.js is a single-threaded application, where a single process handles all the tasks - listening, accepting connections, and reading/writing data.
- This single process creates buffer queues (accept queue and send queue) to manage the incoming connections and data.
- The single process is responsible for listening, accepting connections, and reading/writing data from all the connections asynchronously using the event-driven EPOLL mechanism.
Limitations of the Single Thread
- If there are a large number of connections, the single process may not be able to handle them efficiently, leading to the OS getting "stacked" with connection requests and data.
Scaling with Multiple Node.js Processes
- To address the scalability issue, you can simply spin up multiple Node.js processes, each with its own single-threaded architecture.
- This allows you to take advantage of multiple CPU cores without having to deal with the complexity of multi-threading.
- The OS is shared across the multiple Node.js processes, allowing them to scale horizontally.
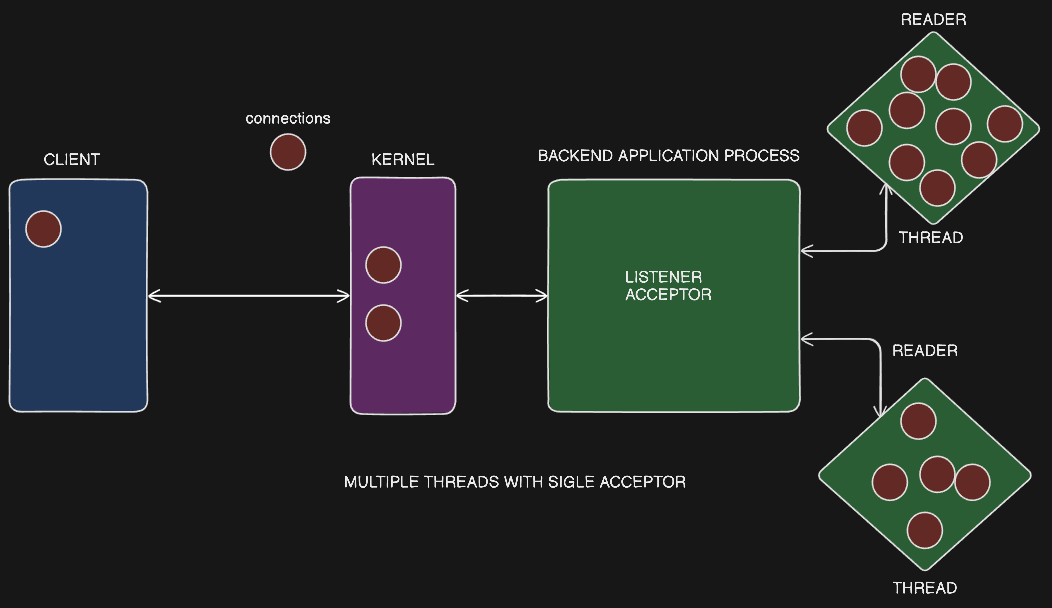
Single Listener, Multiple Worker Threads
- In this architecture, there is a single process that acts as the listener, accepting incoming connections.
- The listener process then assigns the accepted connections to multiple worker threads for processing.
- The worker threads are responsible for reading data from the connections and performing the necessary processing.
Load Balancing Challenges
- The text highlights a potential issue with this architecture - the load may not be evenly distributed across the worker threads.
- One thread could be handling a "greedy" connection that is sending a lot of data, while another thread may have a simple, lightweight connection.
- This can lead to some threads being overloaded while others are underutilized, resulting in suboptimal performance.
Need for Improved Load Balancing
- The text suggests that the single listener, multiple worker threads architecture may not provide true load balancing, as the distribution of work across the threads is not necessarily even.
- This can lead to some threads being heavily loaded while others are idle, which is not an ideal situation.
The text concludes by indicating that the next lecture will explore a solution to the load balancing issue, likely a more advanced architecture or approach to distributing work across multiple threads or processes.
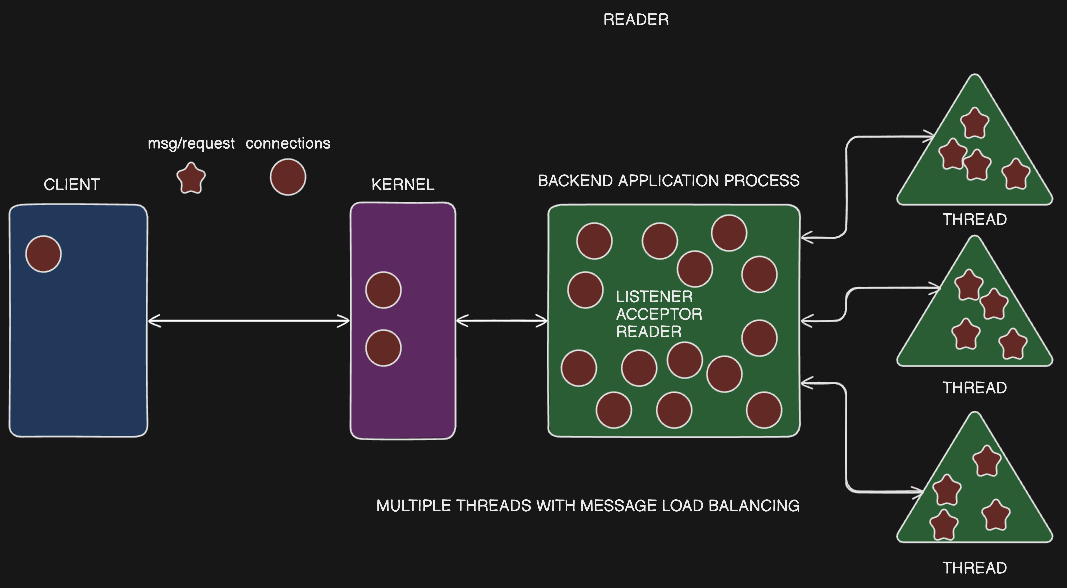
Single Listener/Multiple Worker Threads with Load Balancing
RamCloud's Architecture
- RamCloud has a single listener and single acceptor process, similar to the previous architectures discussed.
- However, RamCloud uses multiple worker threads within this single process.
- The worker threads are responsible for handling the actual requests - decrypting, processing, and preparing the response.
- The worker threads do not directly handle the connections or the connection-level tasks. They only receive the processed requests as messages.
Advantages of RamCloud's Architecture
- This architecture provides true load balancing, as the worker threads only receive the ready-to-process requests, avoiding the issue of some threads being overloaded while others are idle.
- The single listener/acceptor process can become a bottleneck, but this can be addressed by running multiple listener/acceptor processes.
Challenges
- Running multiple listener/acceptor processes requires coordination and awareness of the protocol being used (e.g., HTTP, gRPC), which can be complex to implement.
- Implementing this type of architecture may require programming in low-level languages like C or Rust, as higher-level languages like Go may not provide the necessary control and performance.
The text suggests that the next lecture will cover the approach of running multiple listener/acceptor processes on the same port, which is a technique to address the potential bottleneck of the single listener/acceptor process.
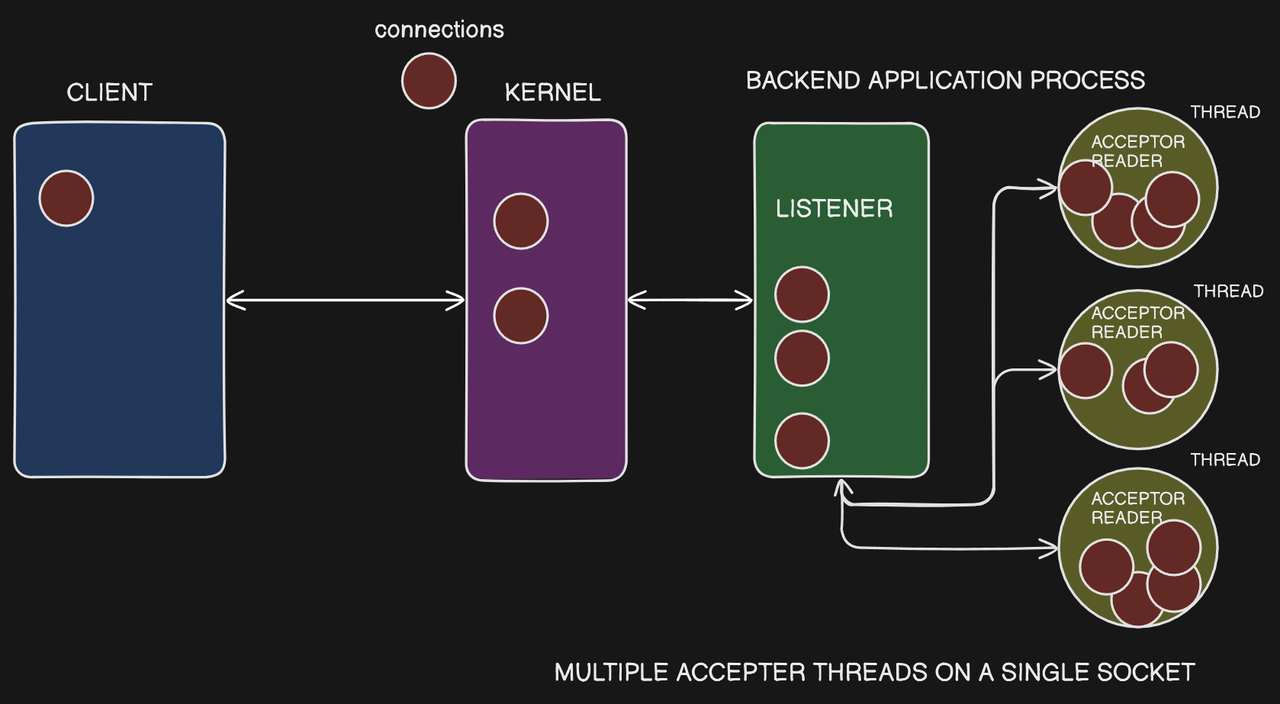
Multiple Threads with a Single Socket
- In this architecture, there is a single listener process that owns the socket.
- The listener process then spawns multiple worker threads that all have access to the same socket object through shared memory.
- Each worker thread can call
accept() on the shared socket to accept incoming connections.
Challenges with Shared Socket
- The issue with this approach is that multiple threads cannot accept connections on the same socket simultaneously, as that would lead to race conditions and concurrency issues.
- To address this, Nginx uses a mutex to control access to the
accept() operation, ensuring that only one thread can accept a connection at a time.
Benefits of Multiple Acceptors
- Despite the need for locking, having multiple acceptor threads is still beneficial when there is a large number of incoming connections in the accept queue.
- The multiple acceptor threads can work in parallel to process the incoming connections, improving overall throughput.
The text concludes by indicating that the next lecture will cover a different approach to handling the connection acceptance and processing.
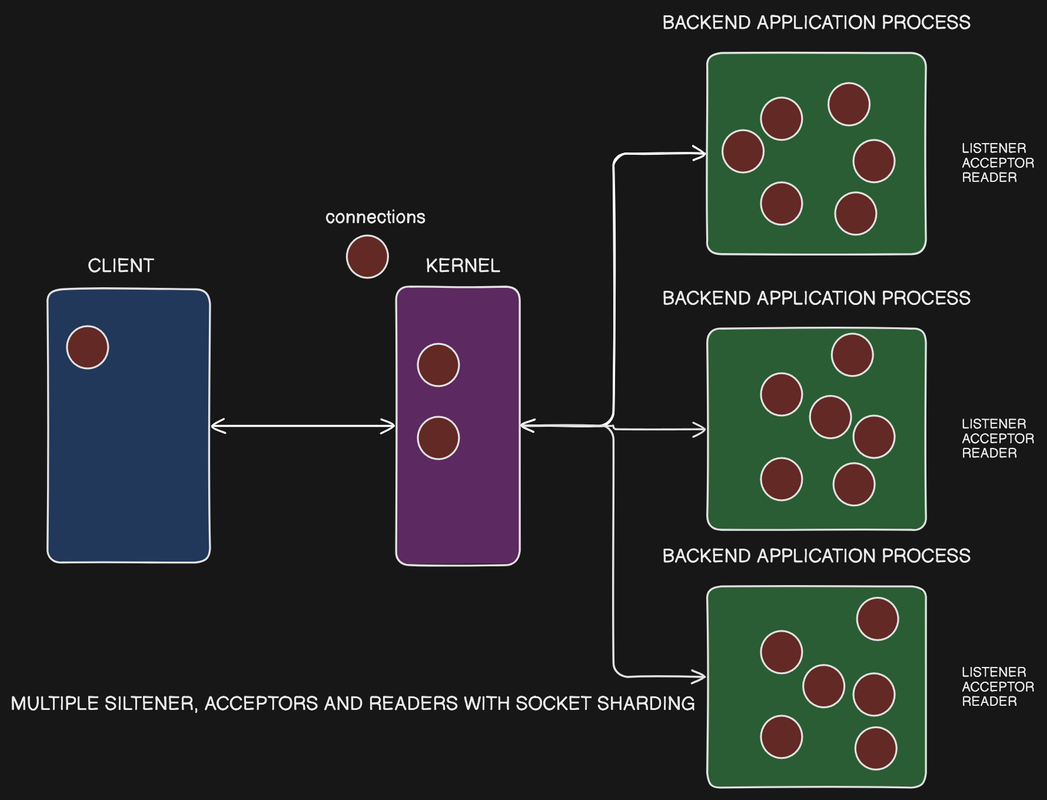
Multiple Listeners on the Same Port (SO_REUSEPORT)
Multiple Listeners on the Same Port
- When you try to have multiple processes listen on the same port and IP address in Node.js, it will typically fail with an "address in use" error.
- However, there is an exception to this - the "socket reuse" or "reuse port" option, which allows multiple processes to listen on the same port.
How Socket Sharding Works
- When the "socket reuse" option is enabled, the operating system (OS) creates multiple accept queues, one for each listening process.
- The OS then distributes the incoming connections across these different accept queues, effectively load balancing the connections across the multiple listener processes.
- Each listener process has its own unique socket ID and only sees the connections that are assigned to its own accept queue, avoiding any race conditions or concurrency issues.
Benefits of Socket Sharding
- Socket sharding is a popular technique used in reverse proxy servers like Nginx and Envoy, as it allows for easy scaling and load balancing of incoming connections.
- The OS handles the distribution of connections across the multiple listener processes, making it a simple and effective solution.
Potential Concerns
- The text mentions that there could be a risk of "port hijacking" if an evil process tries to listen on the same port using the "socket reuse" option.
- The OS has mechanisms in place to prevent this, but it's an important consideration when using this technique.
The text concludes by mentioning that the load balancing problem is still not fully solved, as the distribution of different types of connections (e.g., lightweight HTTP/1.1 vs. complex HTTP/3) across the worker threads may still be uneven. The author suggests that further architectural patterns may be needed to address this issue.
Conclusion
Understanding the intricacies of send and receive buffers, along with the associated challenges and operational modes, is crucial for backend developers aiming to build efficient, scalable, and reliable applications. By carefully choosing the right approach based on the application's specific needs, developers can ensure optimal data handling, minimize latency, and provide a better user experience.